Monitor Linux/Windows VM and applications¶
The configuration of the monitoring for Linux/Windows virtual machines and applications is implemented using fully automated GitOps workflows. You can access those workflows in your administration environment.
Note
In this tutorial, please replace the following values:
ZONE_NAMEwith the name of the administrative zone (it starts withocb-).CUSTOMER_ENVIRONMENTwith the name of the customer environment where virtual machine is located
Principle¶
To monitor a virtual machine (VM) located in one of your customer environments, you have to:
-
install system or application(s) specific Prometheus exporter(s) on this VM
-
declare Prometheus exporters informations in corresponding Git repository in your administration environment
Internal Caascad CI/CD pipelines will validate syntactically exporters informations, create and deploy automatically all necessary Prometheus scrapping configurations.
Important
Ensure that network connectivity exists between Kubernetes® cluster and VM to monitor and it is possible to establish a connection between Prometheus that is running inside the cluster and VM exporter network port.
Install Prometheus exporters¶
According to your monitoring requirements, you can deploy any Prometheus exporter.
There is a wide variety of official and third-party exporters available, so check this list to see if one of them meets your needs.
Here are some installation examples of operating system specific Prometheus exporter:
GitOps Workflow¶
Follow GitOps workflow documentation with feature_name=monitoring-vm
Several actions are possible:
- add/modify informations about the VM(s) which must be monitored
- add/modify informations about exporter(s) used to monitor VMs applications
- remove monitored VM informations
- remove monitored exporter information
Values¶
This section describes all possible configuration values to be specified in Git repository.
Values format¶
Exporters¶
exporters section contains informations about exporters deployed on the VMs from which Prometheus will scrape the metrics.
| Field | Description | Scheme | Required |
|---|---|---|---|
| name | Name of exporter | string: must consist of lower case alphanumeric characters, '-' or '.', and must start and end with an alphanumeric character | true |
| port | Port the exporter metrics is exposed on | int : between 1024 and 65535 | true |
| interval | Interval at which metrics should be scraped | string : must consist of numbers and must end with s |
true |
| path | HTTP path to scrape for metrics | string : must start with / |
true |
| relabelings | Add, modify metrics labels | []*RelabelConfig | false |
| addresses | Addresses specifies the VMs for which Prometheus will scrap the metrics | addresses | true |
Addresses¶
Addresses section contains informations about the VM itself.
| Field | Description | Scheme | Required |
|---|---|---|---|
| hostname | VM's name. Useful to differentiate from which VM the metrics come. | string : must consist of lower case alphanumeric characters or '-', and must start and end with an alphanumeric character | true |
| ip | VM's private IP. IPs must be private. | string | true |
Example¶
exporters:
- name: node-exporter # OS metrics exporter for Linux
port: 9100
interval: 15s
path: /metrics
relabelings:
- replacement: demo_vm_node_exporter
targetLabel: demo_label
addresses:
- hostname: vm-linux-1
ip: 10.0.59.230
- hostname: vm-linux-2
ip: 10.0.21.114
- name: windows-exporter # OS metrics exporter for Windows
port: 9182
interval: 30s
path: /metrics
addresses:
- hostname: vm-windows-3
ip: 10.0.59.235
- hostname: vm-windows-4
ip: 10.0.59.236
In this example, four VMs are monitored:
-
VM 1: ip 10.0.59.230
-
VM 2 : ip 10.0.21.114
-
VM 3 : ip 10.0.59.235
-
VM 4 : ip 10.0.59.236
For the first two VMs, the installed exporter is node_exporter.
For the last two VMs, it's windows_exporter.
Example of metrics retrieved for the last two VMs:
windows_cpu_processor_performance{cc_client="ocb-demo", cc_prom="cloud-app", cc_prom_source="janeway", cc_vm_source="vm-windows-3", core="0,0", endpoint="metrics", instance="10.0.59.235:9182", job="caascad-windows-exporter", namespace="caascad-monitoring-vm", prometheus="monitoring-app/app-prometheus", service="caascad-windows-exporter"} 2168316033206
windows_cpu_processor_performance{cc_client="ocb-demo", cc_prom="cloud-app", cc_prom_source="janeway", cc_vm_source="vm-windows-4", core="0,0", endpoint="metrics", instance="10.0.59.236:9182", job="caascad-windows-exporter", namespace="caascad-monitoring-vm", prometheus="monitoring-app/app-prometheus", service="caascad-windows-exporter"} 2060335251087
The important labels are:
-
cc_prom_source: identifies customer environment. -
cc_vm_source: identifies monitored VM. The value of this label is equal to the value of hostname in the configuration file. -
instance: ip address of the VM with the port of exporter. -
job: the value of this label is equal to caascad-name where name is the value of name in the configuration file.
You can add your own labels in relabelings section.
Troubleshooting¶
If the deployment went well, but metrics are not visible in Grafana, you can check Prometheus target status:
-
connect to customer environment
-
do a port-forward on Prometheus
kubectl port-forward -n caascad-monitoring svc/caascad-prometheus 9090:9090 & -
go to this URL
http://localhost:9090/targets -
check the error message


- If there are connectivity problems, check the private IP of the VM and the security group ...
Alerting¶
It is possible to create PrometheusRules to alert when metrics are no longer scrapped by Prometheus.
Go to: https://git.ZONE_NAME.caascad.com/MonitoringApp/alerts
And follow the README.md to add an alert:
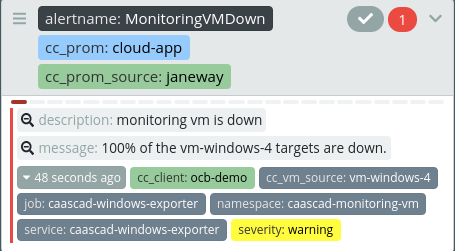
- alert: MonitoringVMDown
annotations:
description: monitoring vm is down
message: '{{ $value }}% of the {{ $labels.cc_vm_source }} targets are down.'
expr: 100 * (count(up{cc_vm_source!=""} == 0) BY (cc_prom_source, cc_vm_source, job, namespace, service) /
count(up{cc_vm_source!=""}) BY (cc_prom_source, cc_vm_source, job, namespace, service)) > 10
for: 10m
labels:
severity: warning
When there is a problem with the VM, an alert will be raised:
Grafana Optionals dashboards¶
To visualise system metrics for Linux or Windows hosts, some predefined Grafana dashboards can be enabled in your customer administration environment.
This is the list of the optional dashboards maintained by Caascad team:
| Dashboard Name | Description | Optional Feature Required |
|---|---|---|
linux-node-exporter |
A dashboard to monitor VMs running on Linux |
|
windows-node-exporter |
A dashboard to monitoring VM running on Windows |
|
GitOps Workflow¶
Follow GitOps workflow documentation with feature_name=grafana-dashboards
Several actions are possible:
- add optional dashboard to Grafana
- remove optional dashboard from Grafana
Values¶
This section describes all possible configuration values to be specified in files in your Caascad Git repositories.
Values format¶
Grafana Dashboards¶
grafana-dashboards section contains informations about the Grafana dashboards that will be deployed on the Grafana application of your zone.
| Field | Description | Scheme | Required |
|---|---|---|---|
<dashboard_name> |
Name of the dashboard | string | true |
<dashboard_name>.enabled |
Enable/disable dashboard | boolean | true |
Example¶
---
grafana_dashboards:
linux-node-exporter:
enabled: true
windows-node-exporter:
enabled: true
In this example, the dashboards linux-node-exporter and windows-node-exporter will be installed.